

On June 26 this year Clinton and Blair made a joint statement saying that the human genome had been sequenced. HUGO (HUman Genome Organization http://www.sanger.ac.uk/HGP/) was formed 1988 to coordinate the different sequencing projects undertaken in different countries. The sequencing started as an international more or less uncoordinated academic effort to sequence the 3 billion (3,000,000,000) letters in the human DNA. The contributions have come from labs all over the planet. The last five years the sequence production has been concentrated in a number of big labs in Japan, USA and Europe. Some of the biggest contributors have been the Sanger Centre, University of Washington, Massachusetts Institute of technology, Baylor College of medicine and RIKEN genome science center. A few years ago a private company, Celera Genomics, entered the race claiming that they would be able to finish the sequencing themselves faster and at a higher accuracy. Under heavy pressure they have agreed to present their results together with the academic research. But we do not have the final sequence yet. What has been produced so far is the raw data. We still have quite a bit to go before we have the finished sequence of the human genome. What the scientists say is that 85% of the human genome has been accurately deciphered. It might still take a couple of years to sort out the rest.
This is a tremendous achievement, also highlighted by the fact that even Clinton and Blair felt the need to keep the human sequence in the public domain. It is the beginning of the post-genome era in biological science. The human genome consists of 46 chromosomes, 23 inherited from the father and 23 from the mother. The chromosomes are numbered according to size; the longest pair has number 1 going down to 22, the sex chromosomes are labeled X and Y. DNA consists of four different nucleotides (A, C, G and T) assembled together in a long polymer (see figure).
When the cell makes a protein it makes it through RNA (ribonucleic acid). RNA is like DNA built from four nucleotides (but using U instead of T). The order of the nucleotides is the same in the RNA as in the DNA (but U for T). It is the linear order of the nucleotides determines what proteins that will be made, eg insulin or albumin. A protein is built from amino acids. There are 20 different amino acids encoded in the DNA (and the RNA) a triplet of nucleotides encodes an amino acid, eg ATG (in DNA, AUG in RNA) means the amino acid methionine. This is the geneitc code and it is universal, i.e. a certain human gene will if introduced into a plant or a bacteria encode the same human protein. If it is made or not will depend on regulatory sequences like promoter sequences, often in front of the coding part of the gene. This is the central dogma of biology, DNA is replicated to be maintained and transcribed to RNA, which is translated into proteins. The flow of information goes from DNA to RNA to protein. |
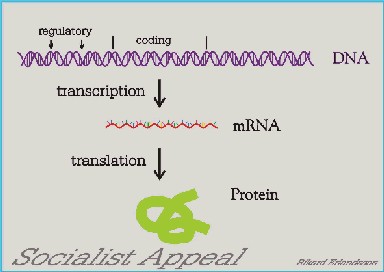 DNA (Deoxyribonucleic acid) is the hereditary material in all lining material. The DNA is copied in every cell division, in a process called replication, so that both daugther cells will have the same DNA as the original cell. DNA is built from four basic building blocks, four different nucleotides (A, C, G and T). It is the linear order of these nucleotides that decides what the DNA is encoding.
DNA (Deoxyribonucleic acid) is the hereditary material in all lining material. The DNA is copied in every cell division, in a process called replication, so that both daugther cells will have the same DNA as the original cell. DNA is built from four basic building blocks, four different nucleotides (A, C, G and T). It is the linear order of these nucleotides that decides what the DNA is encoding.
It is the order of the nucleotides that has been deciphered, sequenced. Some difficult-to-sequence parts like repetitive regions still remain. The chromosomes (i.e. the DNA) carry the genetic information that, in the end, determines our development as human beings. The chromosomes consist of long threads of DNA packaged together with proteins in the nucleus of all our cells. The DNA contains the genes that encode proteins, e.g. hormones and enzymes, regulatory and repetitive sequences.
Now we have the blueprint of the human being. The scientists will still have to decode the different parts of it. But we have also learned a lot during the scientific process, which led to the human sequence. We know that certain genes are involved in the development of cancer. One of the first tumor suppressor genes to be identified was the retinoblastoma gene (RB1) at chromosome 13, published in 1986. Today, we know that a mutation in the RB1 gene is a necessary step on the way to development of the childhood eye tumor, retinoblastoma. It is also possible to screen for mutations in this gene to determine which individuals would benefit from treatment.
Most of what has been learned in the field of genetics and cell biology has been learned through comparisons of normal and tumor cells. In 1981 a link between acute lymphoblastic leukemia (ALL) and specific chromosomal aberrations was established. Almost all patients diagnosed with the disease had chromosomal aberrations involving a specific section of chromosome 9. Scientists have since then been trying to clone and sequence this region to determine what genes have been destroyed by these chromosomal changes. Fifteen years later after an extensive search the enzyme methylthioadenosine phosphorylase, located at chromosome 9 was cloned. More than 95% of all ALL tumors were as expected found to be deficient in this enzyme.
We have already learned the basics from studies of the human genome. Thousands of genes have been identified. With the complete DNA sequence the speed of discovery will be infinitely increased and many new insights will unfold within the next couple of years. Previously, we had a few flashlights focused on different regions that were of special interest. Now, it is more like a chain of streetlights that will help in the understanding of the genome. Now we can see the genome, but we do not understand it yet. We are still lacking a complete catalogue of the genes and genetic elements present in the genome. The field of bioinformatics demands a lot of resources to be able to sort this out.
It will now be possible to determine all genes in the genome and their locations. Chromosomal aberrations in tumors and genetic syndromes will be far easier to associate with specific genes. But there are other ways to associate chromosomal locations with genes besides chromosomal aberrations. One of them is linkage, which is determined as the genetic distance between a genetic locus and a trait. It is possible to map how traits and chromosal markers are inherited in populations and families. Traits that are frequently inherited together with certain genetic markers are located close to them in the genome. The gene BRCA1, is responsible for a part of the hereditary breast cancers. Here linkage studies were part of the scientific discoveries which led to the mapping of BRCA1 to chromosome 17.
When the sequence is known it will be far easier to associate genes with diseases, either through chromosomal aberrations or genetic linkage. Once a disease or a trait has been associated with genetic (i.e. chromosomal) regions there will already be enough information to suggest genes involved in their development. But to establish a causative link between a gene (or genes) and a trait more information is needed, especially about the sequence variation in the population. Why do some individuals develop a certain trait and others don't? This is partly due to differences in their genetic constitutions and partly due to different environmental exposures. To be able to determine what is inherited we need to know how the sequence varies between individuals and what sequence variants that are associated with the trait; e.g. increased risk for heart failure.
This knowledge that will inevitably be generated has to be guarded. We have the individuals right to know if he or she has an increased susceptibility to a disease or not, especially if it is possible to avoid adverse effects through a simple treatment. We now know for instance that one of the causes for hereditary hemochromatosis (iron overload) is due to a mutation in the HFE gene on chromosome 6. The mutation is described and easy to identify and examinations should be offered to all children born to parents known to carry the mutation. This hemochromatosis condition needs only a simple treatment, identical to blood donation. (In Sweden such blood is used as other donated blood in medical health care.) Such treatment will give the patients a normal life otherwise they would almost certainly be dead by the age of 45, due to among other things kidney failure.
But what about a mutated BRCA1 gene that confers an increased risk to develop breast cancer? Of course the individual that might benefit from a change in diet would like to know. But what about the insurance companies which do not want to take unnecessary risks? Or an employer that does not want to hire an individual with a shorter life expectancy? In today's society, based on private companies and profit such knowledge is not only positive for the individual, it might also be used against you. It must be made illegal for a prospective employer to ask for such information. It must on the other hand be made available for anyone who wants to have it, without cost.
The sequencing of the human genome was coordinated among academic institutions more than ten years ago. During the last decade sequences have been published and are publicly available (e.g. GenBank http://www.ncbi.nlm.nih.gov/), free to use as you wish. But a few years back Celera Genomics was formed with money from Perkin-Elmer (one of the biggest biotechnology companies in the world) to compete with the public sequencing initiative. The head of the company, Craig Venter, told everyone that they would finish the sequencing ahead of the academic HUGO project. In April this year Craig Venter said that they were ready with the sequencing of the human genome, obviously in an effort to boost the price of the Celera shares. It was clear that the academic project would be ready, also, much earlier than previously suggested. At the Human Genome Meeting 2000 (HGM 2000) in Vancouver a week after the Celera announcement it was stated that the genome would actually be finished in June this year. In March this year as many new sequences had been deposited in GenBank as during its entire existence up to March. The DNA sequences publicly available had doubled in a single month.
The reason for Celera to enter the race was to get the information first and to protect it from competitors, to patent important sequences to prevent others from using them. But this use of the capitalist right to patent, even some capitalists themselves argue against since it will not generate new products. In this vast field it will just stall new inventions. There is no way a single company would be able to utilize all information that has now been generated.
Now, when the sequence is basically there many new fields for research will open up. Moreover, all sequencing capacity that has been built for the human genome will be freed to study other species and the human variation. Since all living organisms have DNA as their genetic material this capacity can now be used to sequence mouse, chimpanzee, rice, corn etc. This will increase the understanding of our species in relation to nature around us. It will improve the possibility to make sound and safe modifications of plants and animals. The food industry is today completely in the hands of big business. There is no real public control of what is going on. When Greenpeace criticized Novartis for having presented irrelevant research regarding their Bt-corn (modified to kill insects) Novartis replied that the scientific study was properly conducted since the European commission approved it. There were no independent studies made, the EU commission did trust the company. But in the future all this knowledge that has been accumulated will be used for the benefit of mankind and it will be possible to generate new varieties of crops, for instance rice with vitamin A.
It has been known for more than twenty years that the human genetic variation is largely between individuals within populations rather than between populations or continents. This has been confirmed with DNA sequence data over and over again, leaving no genetic base for the theory of races. It has been found that about 85% of the observed genomic variation is between individuals within populations and only 15% among populations. When we now are able to examine differences between individuals in more detail it will open up possibilities that we have never dreamed of. Different traits will be mapped and linked to specific genes, not only deleterious traits but also beneficial ones. To discuss the possibility of genetically modified improved humans today is only absurd.
In September 1999 a young volunteer died during a gene therapy trial at University of Pennsylvania. To get approval of a new medical technique is a lengthy process that requires several years of medical trials. In this particular case it appears that the patient had not been properly examined before the trial, otherwise he would have probably been excluded from the trial. Another gene therapy death was discovered this year at University of Boston. A patient with lung cancer was given treatment with a growth factor that also led increased growth of the tumor. This death was not even properly reported. In both this cases the responsible scientist had economic links to the company which had engineered the treatment. These events show how short-term profit is dictating medical research and putting people in danger. The safety of the patients must be the first priority in every case.
Previously, a big number of bacteria had been sequenced and we have the sequence of the yeast genome. Celera Genetics has also sequenced the fruit fly. And now the human genome will be available for research. We will be able to find out how a human being is created, how the instructions are stored in the genome. In comparison with the mouse we will begin to understand what makes a mammal. Compared with the chimpanzee we will ask; what makes us human? It is an incredibly huge amount of data that will now be available. It will open many new possibilities for treatment of human diseases and in a democratic economy not governed by profit there will be no limits for scientific discoveries and their use for the benefit of mankind.